
RAG笔记
概览
📖 RAG 是什么?
Retrieval-Augmented Generation,检索增强生成。顾名思义,用检索到的信息增强大模型生成的内容,可能是增强准确性,也可能为了增强多样性,总之就是在增强这个大模型的回答。
这项技术可以帮你构建一个更专业的“智能客服”,“知识助手”。
⚙️ 原理
- 检索 (Retrieval)
- 在大模型生成答案前,先从外部知识库(例如数据库、文档集合、向量库、甚至互联网)里检索和问题相关的资料。
- 增强 (Augmented)
- 把这些检索到的资料作为上下文信息,拼接到用户输入里,提供给大模型。
- 生成 (Generation)
- 大模型再基于用户问题 + 外部资料,生成更准确、知识更新的回答。
🌟 为什么需要 RAG?
- 解决 LLM “知识过时” 的问题:大模型的知识是训练时固化的,RAG 可以实时接入外部数据。
- **减少幻觉 (hallucination)**:模型少“瞎编”,因为它有真实的参考资料。
- 灵活可控:你可以决定接入什么知识库,比如企业文档、论文库、代码库等。
📌 应用场景
- 智能问答系统(比如企业知识库问答、学术论文助手)
- 法律/医疗等对准确性要求高的领域
- 搜索增强型聊天机器人
- 文档总结、代码助手
问题
🍗你要给公司做一个智能客服,这样你的客服朋友就会被优化了
需要一个大模型,但是这个大模型不可能了解你家产品,更不可能知道你家产品和其他众多产品的具体差异。
或许可以把公司的各种文档和用户的问题一起交给大模型?
可以的,但是你的文档或许会太长(甚至超过了模型上下文窗口大小,模型会边读边忘),模型找不到准确位置,也难以理解和总结。模型推理成本很高,模型推理很慢。
RAG的思路
🍪如果只把相关的部分文档片段发给模型就好了
RAG 首先将文档切分成片段,根据用户的问题定位具体片段,将片段和问题一起发给大模型。
基本流程
- 在上线之前,准备好文档,完成分片和索引
- 用户提问后,完成召回,重排和生成
分片
分片的方法很多,可以简单的几千字一段,也可以按照章节段落等。
索引
🍡通过 Embedding 将片段转化为向量,然后将向量和片段文本存入数据库。向量可以作为查找到索引(一般几百几千维)
嵌入模型推荐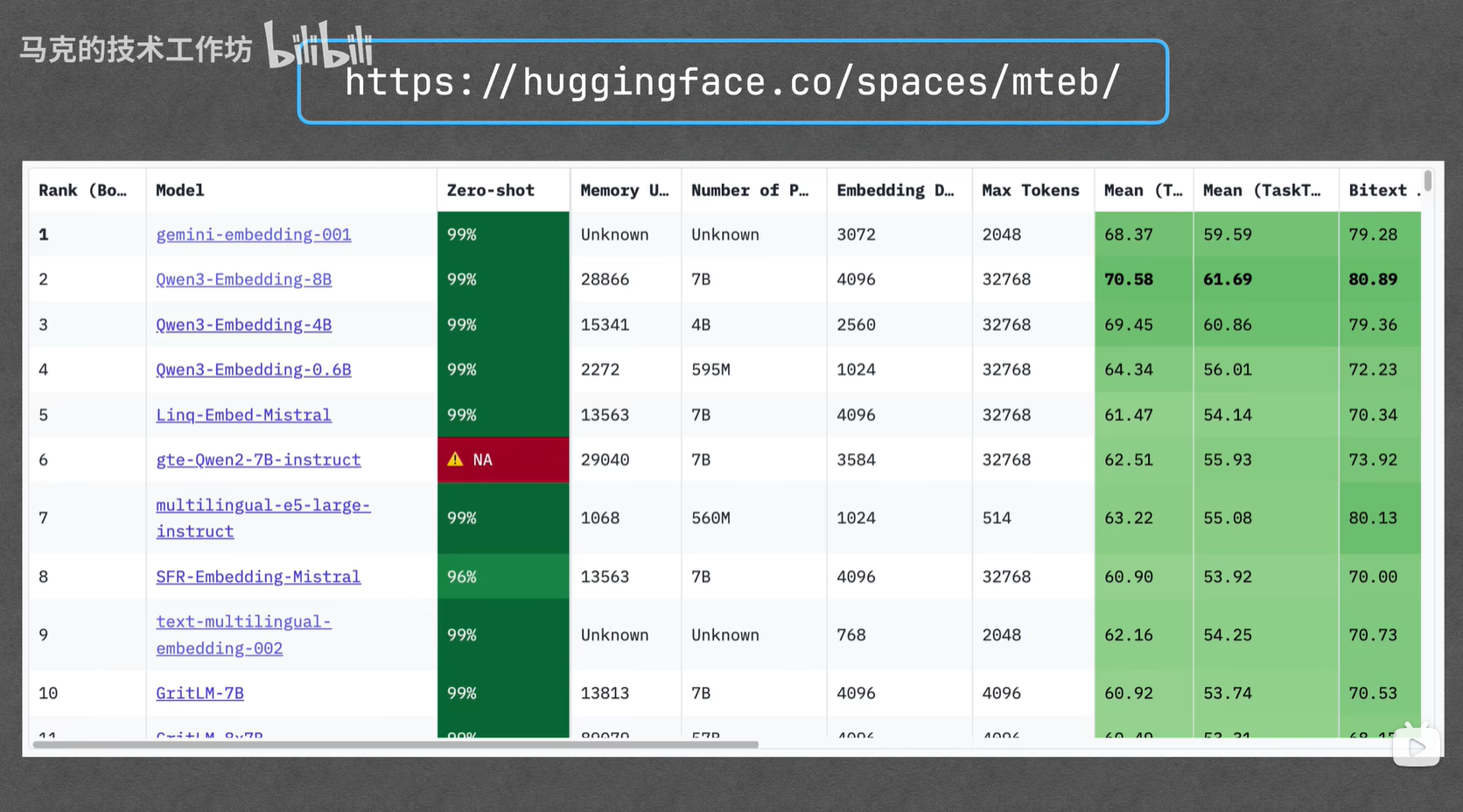
各个片段的嵌入向量会存入向量数据库(原始文本也存),得到嵌入向量并存好的过程就叫索引。
召回
用户提问后,将问题进行嵌入,嵌入后发送到向量数据库,找到若干个(看你想要多少个)相似的嵌入向量,将对应文本片段返回。求相似度一般使用余弦相似度,欧氏距离或者点积。
重排
从召回的片段里选一些和问题最相似。看起来和召回阶段重复,其实两者求相似度的方法不同。
召回阶段,只是为了快速找到合适的片段,准确率低。
重排阶段,使用名为 cross-encoder 的模型计算问题与片段的相似度。准确率高,但更慢。
生成
将筛选到的片段和问题一起发给模型。
参考资料
BV1JLN2z4EZQ
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Peanut🥜!
 支付宝
支付宝
评论



