简介
PyTorch是一个开源的深度学习框架,它由Facebook的人工智能研究实验室(Facebook AI Research, FAIR)开发和维护。该框架提供了灵活的张量计算和动态计算图的功能,使得在深度学习任务中定义和训练神经网络变得更加直观和灵活。
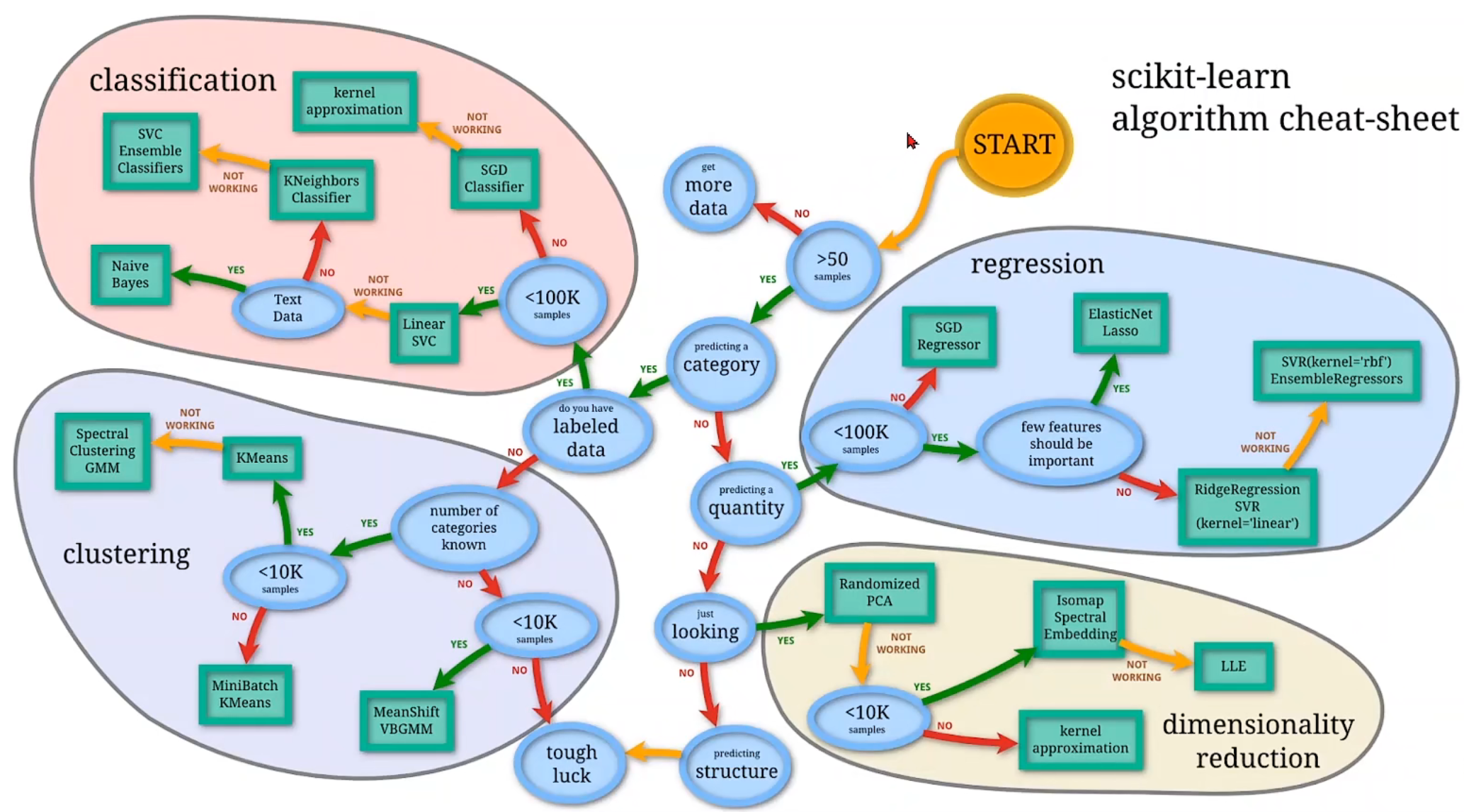
下图是 scikit-learn 官方给的帮助选择算法的图
两个函数
dir():帮助查看某个包里面的内容
help():查看某个函数的用法
数据加载
Dataset 和 Dataloder
Dataset 是一个抽象类,子类需要实现 __getitem__ 方法和 __len__ 方法
path = os.path.join(root_dir, label)
os.path.join 用来拼接两个目录,接收两个字符串,字符串开头和末尾不需要 “\“
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label):
self.root_dir = root_dir
self.label = label
self.path =os.path.join(self.root_dir, self.label)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label,img_name)
img = Image.open(img_item_path)
label = self.label
print(img_name)
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "/home/Disk-2T/suchanghui/dataset/hymenoptera_data/train"
label = "ants"
ants_dataset = MyData(root_dir,label)
img, label = ants_dataset[1]
img.save("/home/Disk-2T/suchanghui/pytorch/1.png")
|
用自己定义的 MyData 类和不同的数据文件夹创建了多个 ***_dataset 实例,这些实例可以直接相加组成一个大的数据集:
train_dataset = ants_dataset + bees_dataset
Tensorboard 的使用

 支付宝
支付宝


