
强化学习
参考资料:
简介
于监督学习或无监督学习不同,强化学习不是从静态数据集中学习知识,而是与动态环境交互;目标也不是对数据进行分类或标记,而是找到能够产生最优结果的最佳动作序列。从这个意义上说,”最优“意味着获得最多的奖励。
上大学(Action),得到一份工作(Observation/state),得到工资(Reward)
过马路前看了两边(Action),到了马路另一边(State),没有被撞到(Reward)
在智能体内部有一个大脑,它接受状态观测量(输入),并将它们映射到动作(输出)中。在 RL 术语中,这种映射被称“策略”(policy)。如果提供一组观测量,策略便会确定要采取的动作。
强化学习算法则会根据以上三者,更新策略(因为环境可能在变化,策略也可能还不够好)
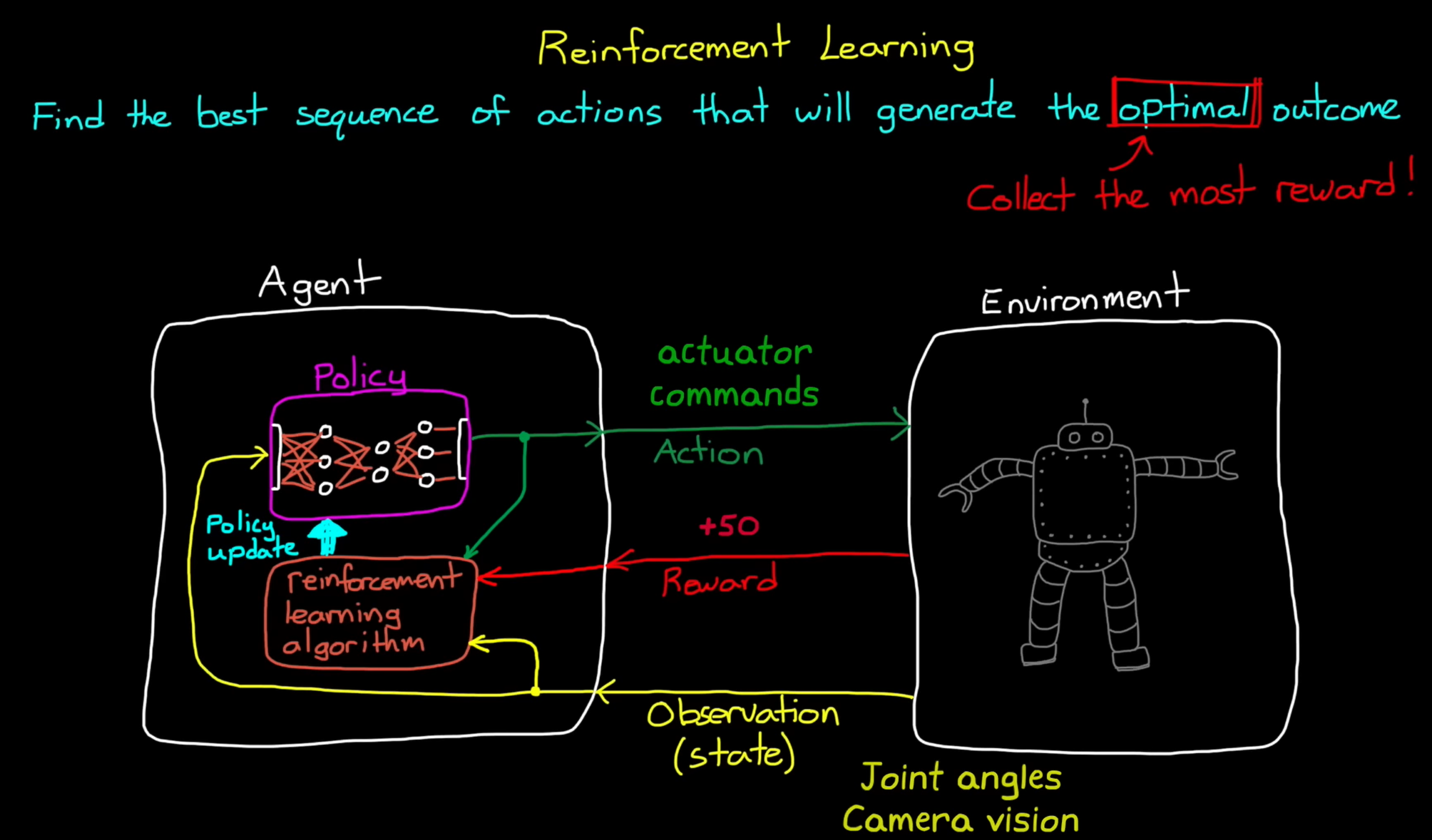
强化学习也是一种优化问题,需要区分两个概念:
Value:从当前状态到未来,所能获得激励的总和。
Reward:当前状态的即时的激励。
强化学习的目标是最大化 Value。
像金融市场一样,对未来的预测总是不可靠的。强化学习会通过一些设计,对未来的收益进行“折扣”,让自己更目光短浅一点。
同时,为了让算法能够发现更好的选择,我们偶尔会允许它去“冒险”尝试一些当下低收益的事情。
有时候为了避免激励来得太晚,会在中间设置激励,但也有弊端,比如机器人发现只要往地上一躺就拿到了激励。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Peanut🥜!
 支付宝
支付宝
评论



